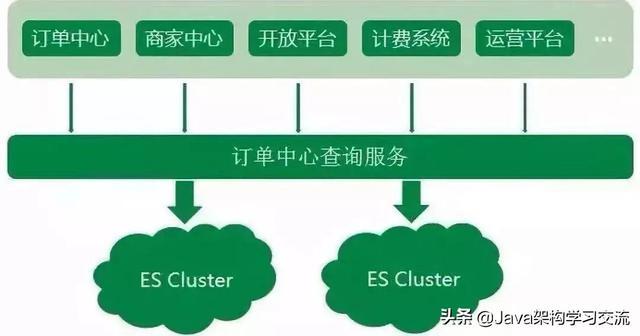
京東到家訂單中心系統(tǒng)業(yè)務(wù)中,無(wú)論是外部商家的訂單生產(chǎn)�����,或是內(nèi)部上下游系統(tǒng)的依賴��,訂單查詢的調(diào)用量都非常大��,造成了訂單數(shù)據(jù)讀多寫(xiě)少的情況�。
我們把訂單數(shù)據(jù)存儲(chǔ)在MySQL中����,但顯然只通過(guò)DB來(lái)支撐大量的查詢是不可取的。同時(shí)對(duì)于一些復(fù)雜的查詢�����,MySQL支持得不夠友好���,所以訂單中心系統(tǒng)使用了Elasticsearch來(lái)承載訂單查詢的主要壓力��。
Elasticsearch作為一款功能強(qiáng)大的分布式搜索引擎�����,支持近實(shí)時(shí)的存儲(chǔ)��、搜索數(shù)據(jù)�����,在京東到家訂單系統(tǒng)中發(fā)揮著巨大作用���,目前訂單中心ES集群存儲(chǔ)數(shù)據(jù)量達(dá)到10億個(gè)文檔����,日均查詢量達(dá)到5億���。
隨著京東到家近幾年業(yè)務(wù)的快速發(fā)展�����,訂單中心ES架設(shè)方案也不斷演進(jìn)����,發(fā)展至今ES集群架設(shè)是一套實(shí)時(shí)互備方案�,很好地保障了ES集群讀寫(xiě)的穩(wěn)定性,下面就給大家介紹一下這個(gè)歷程以及過(guò)程中遇到的一些坑。
ES 集群架構(gòu)演進(jìn)之路
1�����、初始階段
訂單中心ES初始階段如一張白紙����,架設(shè)方案基本沒(méi)有,很多配置都是保持集群默認(rèn)配置�����。整個(gè)集群部署在集團(tuán)的彈性云上���,ES集群的節(jié)點(diǎn)以及機(jī)器部署都比較混亂���。同時(shí)按照集群維度來(lái)看���,一個(gè)ES集群會(huì)有單點(diǎn)問(wèn)題���,顯然對(duì)于訂單中心業(yè)務(wù)來(lái)說(shuō)也是不被允許的。
2�、集群隔離階段
和很多業(yè)務(wù)一樣,ES集群采用的混布的方式。但由于訂單中心ES存儲(chǔ)的是線上訂單數(shù)據(jù)�����,偶爾會(huì)發(fā)生混布集群搶占系統(tǒng)大量資源��,導(dǎo)致整個(gè)訂單中心ES服務(wù)異常����。
顯然任何影響到訂單查詢穩(wěn)定性的情況都是無(wú)法容忍的,所以針對(duì)于這個(gè)情況����,先是對(duì)訂單中心ES所在的彈性云,遷出那些系統(tǒng)資源搶占很高的集群節(jié)點(diǎn)����,ES集群狀況稍有好轉(zhuǎn)。但隨著集群數(shù)據(jù)不斷增加����,彈性云配置已經(jīng)不太能滿足ES集群,且為了完全的物理隔離��,最終干脆將訂單中心ES集群部署到高配置的物理機(jī)上��,ES集群性能又得到提升。
3����、節(jié)點(diǎn)副本調(diào)優(yōu)階段
ES的性能跟硬件資源有很大關(guān)系,當(dāng)ES集群?jiǎn)为?dú)部署到物理機(jī)器上時(shí)���,集群內(nèi)部的節(jié)點(diǎn)并不是獨(dú)占整臺(tái)物理機(jī)資源��,在集群運(yùn)行的時(shí)候同一物理機(jī)上的節(jié)點(diǎn)仍會(huì)出現(xiàn)資源搶占的問(wèn)題����。所以在這種情況下����,為了讓ES單個(gè)節(jié)點(diǎn)能夠使用最大程度的機(jī)器資源,采用每個(gè)ES節(jié)點(diǎn)部署在單獨(dú)一臺(tái)物理機(jī)上方式�����。
但緊接著���,問(wèn)題又來(lái)了,如果單個(gè)節(jié)點(diǎn)出現(xiàn)瓶頸了呢�����?我們應(yīng)該怎么再優(yōu)化呢?
ES查詢的原理�,當(dāng)請(qǐng)求打到某號(hào)分片的時(shí)候,如果沒(méi)有指定分片類型(Preference參數(shù))查詢����,請(qǐng)求會(huì)負(fù)載到對(duì)應(yīng)分片號(hào)的各個(gè)節(jié)點(diǎn)上。而集群默認(rèn)副本配置是一主一副���,針對(duì)此情況���,我們想到了擴(kuò)容副本的方式,由默認(rèn)的一主一副變?yōu)橐恢鞫?����,同時(shí)增加相應(yīng)物理機(jī)���。
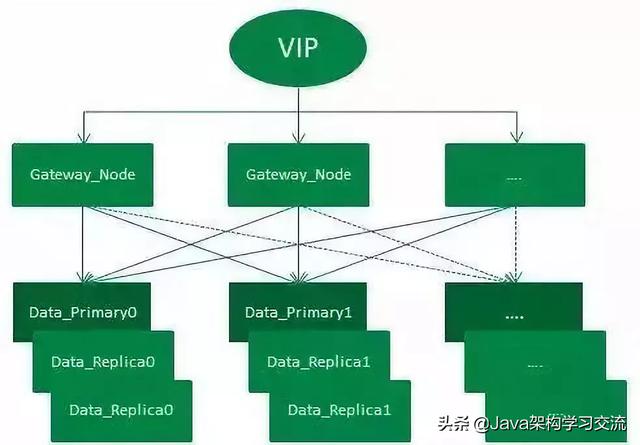
訂單中心ES集群架設(shè)示意圖
如圖����,整個(gè)架設(shè)方式通過(guò)VIP來(lái)負(fù)載均衡外部請(qǐng)求:
整個(gè)集群有一套主分片�����,二套副分片(一主二副),從網(wǎng)關(guān)節(jié)點(diǎn)轉(zhuǎn)發(fā)過(guò)來(lái)的請(qǐng)求����,會(huì)在打到數(shù)據(jù)節(jié)點(diǎn)之前通過(guò)輪詢的方式進(jìn)行均衡。集群增加一套副本并擴(kuò)容機(jī)器的方式�����,增加了集群吞吐量�,從而提升了整個(gè)集群查詢性能。
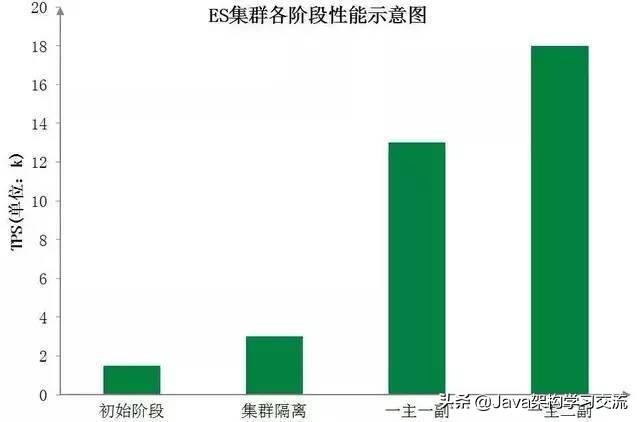
下圖為訂單中心ES集群各階段性能示意圖���,直觀地展示了各階段優(yōu)化后ES集群性能的顯著提升:
當(dāng)然分片數(shù)量和分片副本數(shù)量并不是越多越好��,在此階段�,我們對(duì)選擇適當(dāng)?shù)姆制瑪?shù)量做了進(jìn)一步探索�。分片數(shù)可以理解為MySQL中的分庫(kù)分表,而當(dāng)前訂單中心ES查詢主要分為兩類:?jiǎn)蜪D查詢以及分頁(yè)查詢��。
分片數(shù)越大�,集群橫向擴(kuò)容規(guī)模也更大,根據(jù)分片路由的單ID查詢吞吐量也能大大提升�����,但聚合的分頁(yè)查詢性能則將降低�;分片數(shù)越小,集群橫向擴(kuò)容規(guī)模也更小�����,單ID的查詢性能也會(huì)下降�����,但分頁(yè)查詢的性能將會(huì)提升���。
所以如何均衡分片數(shù)量和現(xiàn)有查詢業(yè)務(wù)���,我們做了很多次調(diào)整壓測(cè),最終選擇了集群性能較好的分片數(shù)���。
4�����、主從集群調(diào)整階段
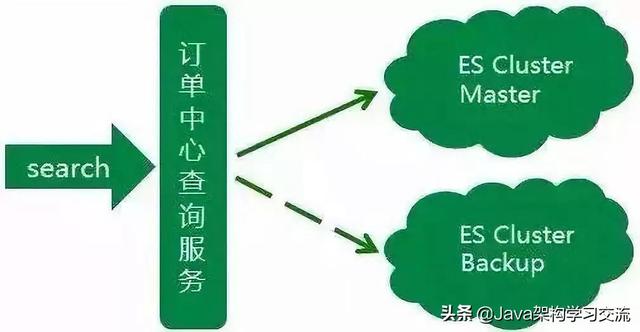
到此��,訂單中心的ES集群已經(jīng)初具規(guī)模�,但由于訂單中心業(yè)務(wù)時(shí)效性要求高,對(duì)ES查詢穩(wěn)定性要求也高�����,如果集群中有節(jié)點(diǎn)發(fā)生異常��,查詢服務(wù)會(huì)受到影響����,從而影響到整個(gè)訂單生產(chǎn)流程。很明顯這種異常情況是致命的�����,所以為了應(yīng)對(duì)這種情況��,我們初步設(shè)想是增加一個(gè)備用集群����,當(dāng)主集群發(fā)生異常時(shí),可以實(shí)時(shí)的將查詢流量降級(jí)到備用集群�����。
那備用集群應(yīng)該怎么來(lái)搭?主備之間數(shù)據(jù)如何同步�����?備用集群應(yīng)該存儲(chǔ)什么樣的數(shù)據(jù)���?
考慮到ES集群暫時(shí)沒(méi)有很好的主備方案,同時(shí)為了更好地控制ES數(shù)據(jù)寫(xiě)入����,我們采用業(yè)務(wù)雙寫(xiě)的方式來(lái)搭設(shè)主備集群。每次業(yè)務(wù)操作需要寫(xiě)入ES數(shù)據(jù)時(shí)�����,同步寫(xiě)入主集群數(shù)據(jù)���,然后異步寫(xiě)入備集群數(shù)據(jù)���。同時(shí)由于大部分ES查詢的流量都來(lái)源于近幾天的訂單,且訂單中心數(shù)據(jù)庫(kù)數(shù)據(jù)已有一套歸檔機(jī)制�,將指定天數(shù)之前已經(jīng)關(guān)閉的訂單轉(zhuǎn)移到歷史訂單庫(kù)。
所以歸檔機(jī)制中增加刪除備集群文檔的邏輯,讓新搭建的備集群存儲(chǔ)的訂單數(shù)據(jù)與訂單中心線上數(shù)據(jù)庫(kù)中的數(shù)據(jù)量保持一致����。同時(shí)使用ZK在查詢服務(wù)中做了流量控制開(kāi)關(guān),保證查詢流量能夠?qū)崟r(shí)降級(jí)到備集群���。在此����,訂單中心主從集群完成��,ES查詢服務(wù)穩(wěn)定性大大提升��。
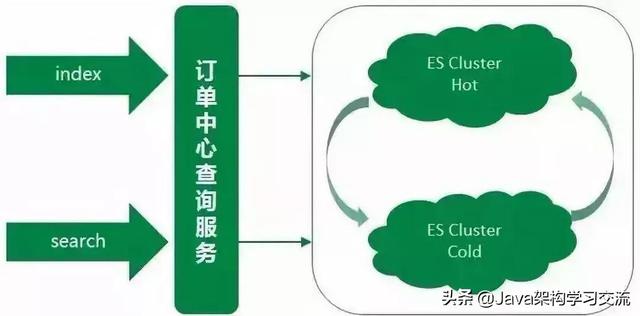
5���、現(xiàn)今:實(shí)時(shí)互備雙集群階段
期間由于主集群ES版本是較低的1.7����,而現(xiàn)今ES穩(wěn)定版本都已經(jīng)迭代到6.x��,新版本的ES不僅性能方面優(yōu)化很大�,更提供了一些新的好用的功能,所以我們對(duì)主集群進(jìn)行了一次版本升級(jí)���,直接從原來(lái)的1.7升級(jí)到6.x版本�����。
集群升級(jí)的過(guò)程繁瑣而漫長(zhǎng)��,不但需要保證線上業(yè)務(wù)無(wú)任何影響�����,平滑無(wú)感知升級(jí)���,同時(shí)由于ES集群暫不支持從1.7到6.x跨越多個(gè)版本的數(shù)據(jù)遷移,所以需要通過(guò)重建索引的方式來(lái)升級(jí)主集群��,具體升級(jí)過(guò)程就不在此贅述了�����。
主集群升級(jí)的時(shí)候必不可免地會(huì)發(fā)生不可用的情況�����,但對(duì)于訂單中心ES查詢服務(wù)����,這種情況是不允許的��。所以在升級(jí)的階段中���,備集群暫時(shí)頂上充當(dāng)主集群,來(lái)支撐所有的線上ES查詢����,保證升級(jí)過(guò)程不影響正常線上服務(wù)。同時(shí)針對(duì)于線上業(yè)務(wù)�����,我們對(duì)兩個(gè)集群做了重新的規(guī)劃定義�����,承擔(dān)的線上查詢流量也做了重新的劃分�����。
備集群存儲(chǔ)的是線上近幾天的熱點(diǎn)數(shù)據(jù)�����,數(shù)據(jù)規(guī)模遠(yuǎn)小于主集群,大約是主集群文檔數(shù)的十分之一�����。集群數(shù)據(jù)量小��,在相同的集群部署規(guī)模下�,備集群的性能要優(yōu)于主集群。
然而在線上真實(shí)場(chǎng)景中��,線上大部分查詢流量也來(lái)源于熱點(diǎn)數(shù)據(jù)���,所以用備集群來(lái)承載這些熱點(diǎn)數(shù)據(jù)的查詢,而備集群也慢慢演變成一個(gè)熱數(shù)據(jù)集群����。之前的主集群存儲(chǔ)的是全量數(shù)據(jù),用該集群來(lái)支撐剩余較小部分的查詢流量�,這部分查詢主要是需要搜索全量訂單的特殊場(chǎng)景查詢以及訂單中心系統(tǒng)內(nèi)部查詢等,而主集群也慢慢演變成一個(gè)冷數(shù)據(jù)集群����。
同時(shí)備集群增加一鍵降級(jí)到主集群的功能,兩個(gè)集群地位同等重要����,但都可以各自降級(jí)到另一個(gè)集群�����。雙寫(xiě)策略也優(yōu)化為:假設(shè)有AB集群��,正常同步方式寫(xiě)主(A集群)異步方式寫(xiě)備(B集群)�����。A集群發(fā)生異常時(shí)���,同步寫(xiě)B(tài)集群(主),異步寫(xiě)A集群(備)����。
ES 訂單數(shù)據(jù)的同步方案
MySQL數(shù)據(jù)同步到ES中,大致總結(jié)可以分為兩種方案:
方案1:監(jiān)聽(tīng)MySQL的Binlog���,分析Binlog將數(shù)據(jù)同步到ES集群中���。
方案2:直接通過(guò)ES API將數(shù)據(jù)寫(xiě)入到ES集群中。
考慮到訂單系統(tǒng)ES服務(wù)的業(yè)務(wù)特殊性���,對(duì)于訂單數(shù)據(jù)的實(shí)時(shí)性較高����,顯然監(jiān)聽(tīng)Binlog的方式相當(dāng)于異步同步,有可能會(huì)產(chǎn)生較大的延時(shí)性����。且方案1實(shí)質(zhì)上跟方案2類似,但又引入了新的系統(tǒng)��,維護(hù)成本也增高�。所以訂單中心ES采用了直接通過(guò)ES API寫(xiě)入訂單數(shù)據(jù)的方式,該方式簡(jiǎn)潔靈活��,能夠很好的滿足訂單中心數(shù)據(jù)同步到ES的需求���。
由于ES訂單數(shù)據(jù)的同步采用的是在業(yè)務(wù)中寫(xiě)入的方式,當(dāng)新建或更新文檔發(fā)生異常時(shí)���,如果重試勢(shì)必會(huì)影響業(yè)務(wù)正常操作的響應(yīng)時(shí)間����。
所以每次業(yè)務(wù)操作只更新一次ES��,如果發(fā)生錯(cuò)誤或者異常,在數(shù)據(jù)庫(kù)中插入一條補(bǔ)救任務(wù)����,有Worker任務(wù)會(huì)實(shí)時(shí)地掃這些數(shù)據(jù),以數(shù)據(jù)庫(kù)訂單數(shù)據(jù)為基準(zhǔn)來(lái)再次更新ES數(shù)據(jù)��。通過(guò)此種補(bǔ)償機(jī)制���,來(lái)保證ES數(shù)據(jù)與數(shù)據(jù)庫(kù)訂單數(shù)據(jù)的最終一致性��。
遇到的一些坑
1�、實(shí)時(shí)性要求高的查詢走DB
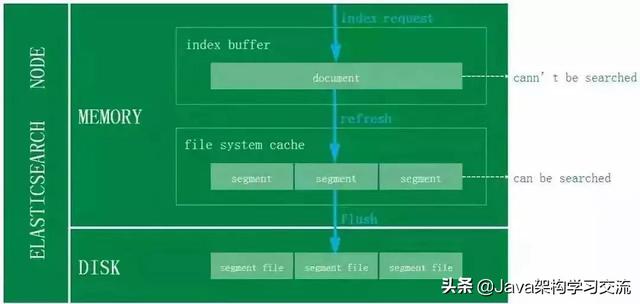
對(duì)于ES寫(xiě)入機(jī)制的有了解的同學(xué)可能會(huì)知道�,新增的文檔會(huì)被收集到Indexing Buffer,然后寫(xiě)入到文件系統(tǒng)緩存中�����,到了文件系統(tǒng)緩存中就可以像其他的文件一樣被索引到����。
然而默認(rèn)情況文檔從Indexing Buffer到文件系統(tǒng)緩存(即Refresh操作)是每秒分片自動(dòng)刷新,所以這就是我們說(shuō)ES是近實(shí)時(shí)搜索而非實(shí)時(shí)的原因:文檔的變化并不是立即對(duì)搜索可見(jiàn)�,但會(huì)在一秒之內(nèi)變?yōu)榭梢?jiàn)。
當(dāng)前訂單系統(tǒng)ES采用的是默認(rèn)Refresh配置�,故對(duì)于那些訂單數(shù)據(jù)實(shí)時(shí)性比較高的業(yè)務(wù)���,直接走數(shù)據(jù)庫(kù)查詢,保證數(shù)據(jù)的準(zhǔn)確性�����。
2�����、避免深分頁(yè)查詢
ES集群的分頁(yè)查詢支持from和size參數(shù)���,查詢的時(shí)候�����,每個(gè)分片必須構(gòu)造一個(gè)長(zhǎng)度為from+size的優(yōu)先隊(duì)列��,然后回傳到網(wǎng)關(guān)節(jié)點(diǎn)�,網(wǎng)關(guān)節(jié)點(diǎn)再對(duì)這些優(yōu)先隊(duì)列進(jìn)行排序找到正確的size個(gè)文檔�。
假設(shè)在一個(gè)有6個(gè)主分片的索引中�,from為10000,size為10���,每個(gè)分片必須產(chǎn)生10010個(gè)結(jié)果���,在網(wǎng)關(guān)節(jié)點(diǎn)中匯聚合并60060個(gè)結(jié)果�����,最終找到符合要求的10個(gè)文檔�����。
由此可見(jiàn)�����,當(dāng)from足夠大的時(shí)候�,就算不發(fā)生OOM����,也會(huì)影響到CPU和帶寬等,從而影響到整個(gè)集群的性能����。所以應(yīng)該避免深分頁(yè)查詢,盡量不去使用。
3��、FieldData與Doc Values
FieldData
線上查詢出現(xiàn)偶爾超時(shí)的情況���,通過(guò)調(diào)試查詢語(yǔ)句�����,定位到是跟排序有關(guān)系����。排序在es1.x版本使用的是FieldData結(jié)構(gòu)����,F(xiàn)ieldData占用的是JVM Heap內(nèi)存,JVM內(nèi)存是有限����,對(duì)于FieldData Cache會(huì)設(shè)定一個(gè)閾值。
如果空間不足時(shí)���,使用最久未使用(LRU)算法移除FieldData�,同時(shí)加載新的FieldData Cache�,加載的過(guò)程需要消耗系統(tǒng)資源���,且耗時(shí)很大��。所以導(dǎo)致這個(gè)查詢的響應(yīng)時(shí)間暴漲�,甚至影響整個(gè)集群的性能。針對(duì)這種問(wèn)題��,解決方式是采用Doc Values��。
Doc Values
Doc Values是一種列式的數(shù)據(jù)存儲(chǔ)結(jié)構(gòu)��,跟FieldData很類似��,但其存儲(chǔ)位置是在Lucene文件中���,即不會(huì)占用JVM Heap����。隨著ES版本的迭代��,Doc Values比FieldData更加穩(wěn)定�,Doc Values在2.x起為默認(rèn)設(shè)置。
總結(jié)
架構(gòu)的快速迭代源于業(yè)務(wù)的快速發(fā)展����,正是由于近幾年到家業(yè)務(wù)的高速發(fā)展�����,訂單中心的架構(gòu)也不斷優(yōu)化升級(jí)�����。而架構(gòu)方案沒(méi)有最好的�����,只有最合適的��,相信再過(guò)幾年�,訂單中心的架構(gòu)又將是另一個(gè)面貌�����,但吞吐量更大���,性能更好���,穩(wěn)定性更強(qiáng)�,將是訂單中心系統(tǒng)永遠(yuǎn)的追求��。


 贛公網(wǎng)安備 36050202000267號(hào)
贛公網(wǎng)安備 36050202000267號(hào)




